Introduction
Evals let you measure the quality of your calls with LLM judges. You define eval agents, each of which grades one dimension of a call (resolution, tone, hallucination, audio quality, and so on), then run them against a batch of real or test calls to get per-call verdicts and aggregate scores. Use Evals to track quality over time, compare prompt or pathway changes, and catch regressions before they reach production. You can build and run Evals from the Evals section of the dashboard, or drive the entire workflow through the Evals API.Eval agents
Configurable LLM judges. Each grades one quality of every call against an instruction prompt and a set of graded levels.
Experiments
Score a batch of calls against a group of eval agents in one run. Get per-call verdicts plus an aggregate score and pass/fail.
Workbench setups
Save a reusable bundle of agents, weights, targets, and a pass threshold so the same composition re-runs with a stable identity.
Templates
Start from a shipped template like Hallucination Detection or Resolution, or save your own agents as reusable templates.
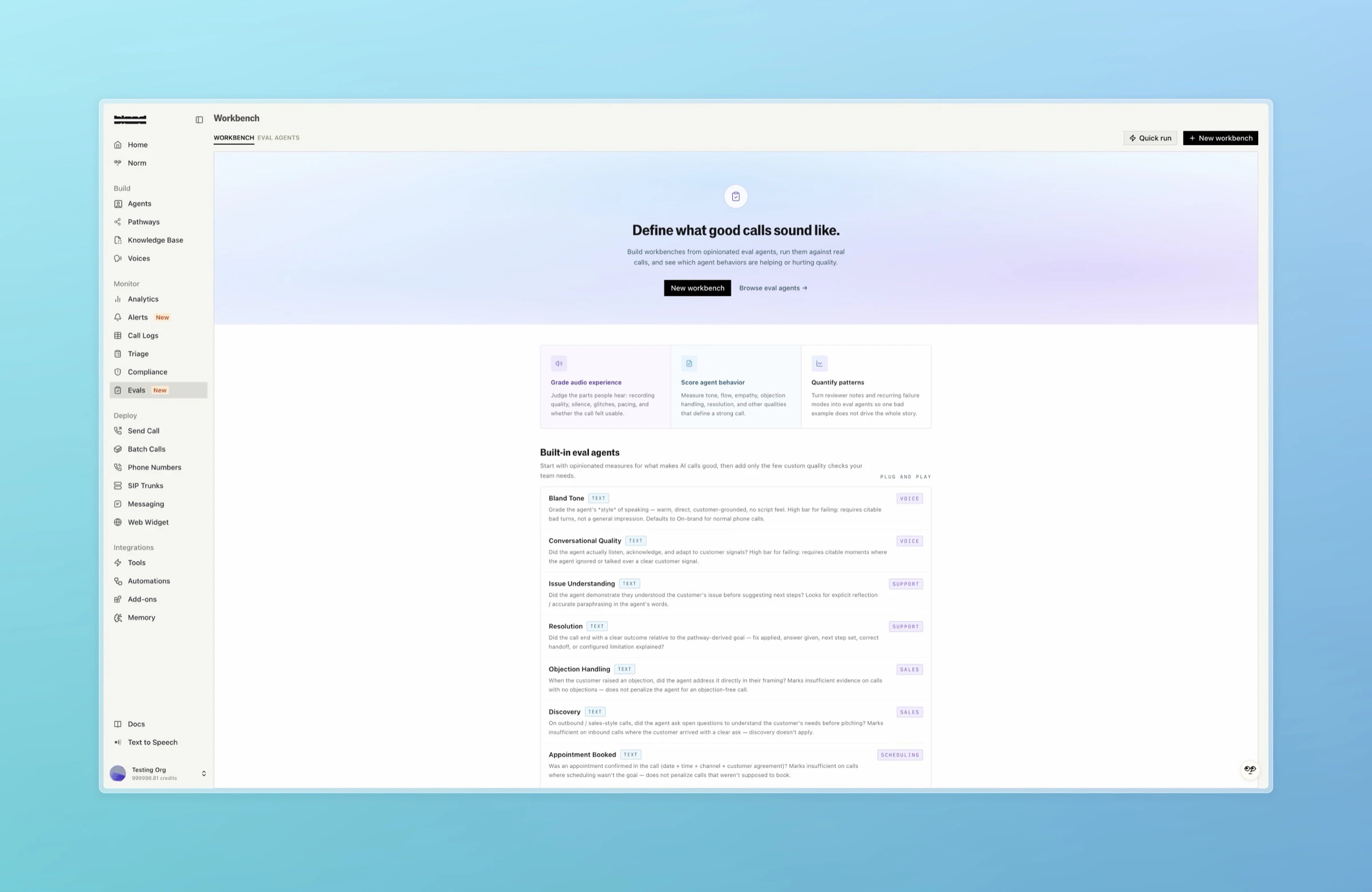
Core concepts
Eval agents
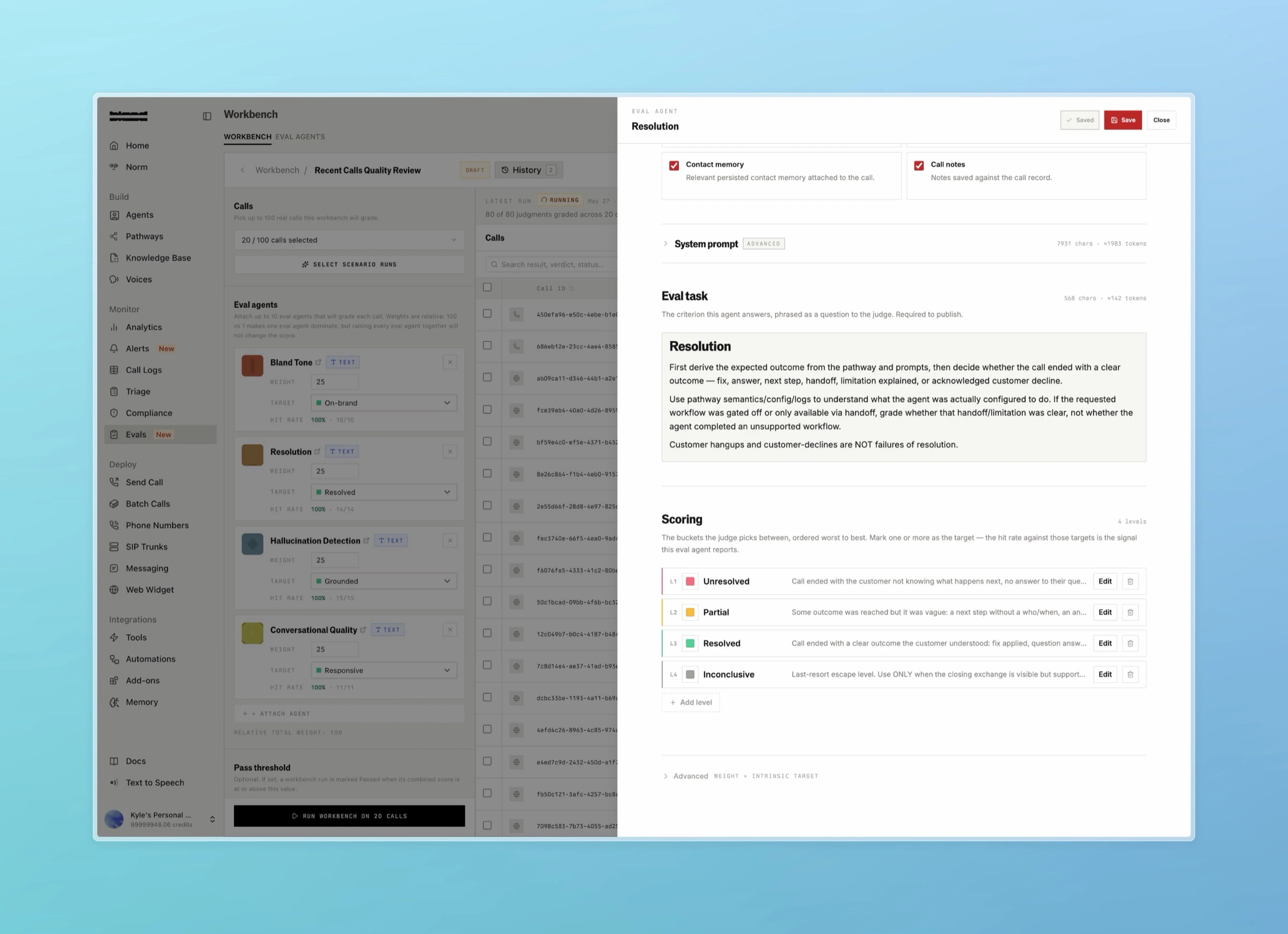
An eval agent is a single LLM judge that grades one quality of a call. Each agent has:- Instruction prompt: the rubric the judge follows when grading a call.
- Modality:
text(grades the transcript) oraudio(grades the recording). - Levels: the verdicts the judge can choose from. An agent runs in one of two modes:
- Pass/fail:
0levels. The judge returns a simple pass or fail. - Graded:
2to5levels (for example Poor, Adequate, Excellent). Each level has a key, a label, a description prompt, and an optional color.
- Pass/fail:
- Target levels: which levels count as “hitting the target.” Used to compute hit rate. Pass/fail agents do not set targets.
- Weight:
0to100. Controls how much this agent contributes to a call’s overall score when it runs alongside other agents.
Versions
Eval agents are versioned. Editing an agent writes your changes into an editable draft version. Publishing snapshots that draft into a new archived version and points the agent’s active version at it. Two pointers track this:current_version_id: the working draft you edit.active_version_id: the published version that experiments run against.
Verdicts
When a judge grades a call, it returns a verdict for that call and agent: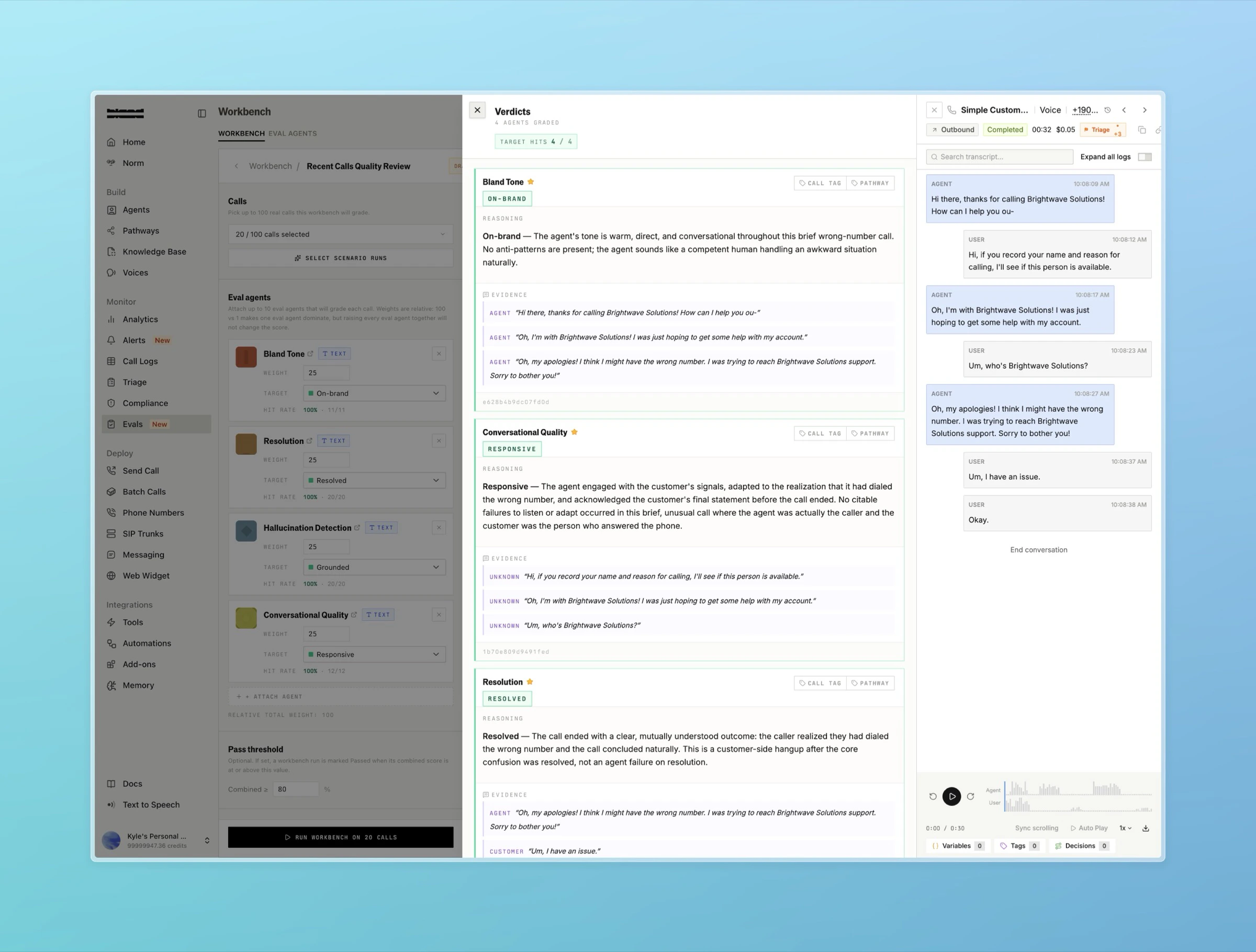
Experiments
An experiment (an eval run in the API) is one batch of calls scored by one group of eval agents. You submit:- Calls: up to 5,000 call IDs per run.
- Attached agents: up to 50 agents, each with a weight and target levels for this run.
- Run mode:
text,audio, orfull. Controls which agents score against each call based on modality. - Pass threshold: the percentage at or above which the run counts as an overall pass.
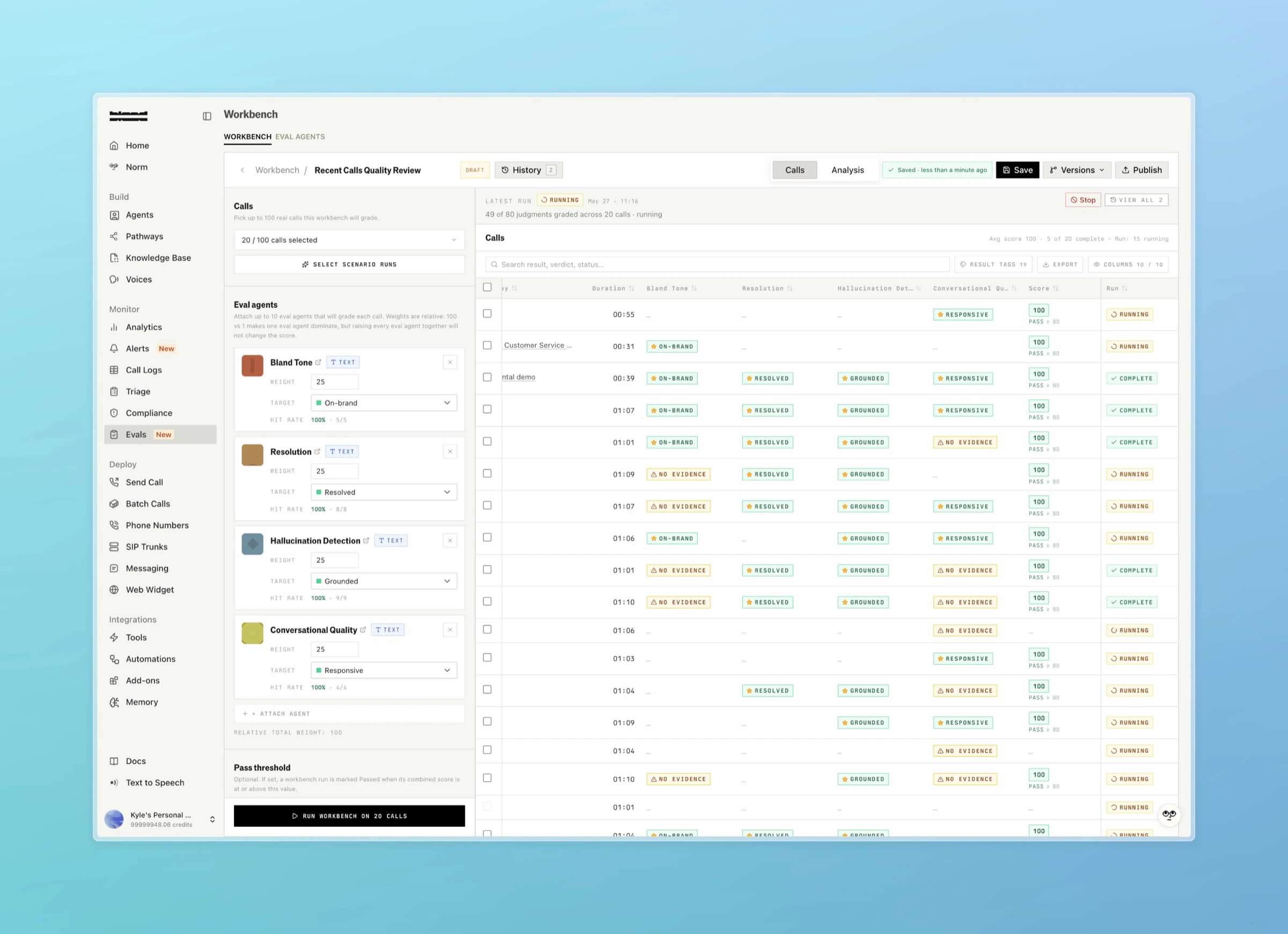
- Per-call results: the aggregate score for each call plus each agent’s verdict on it.
- Per-agent results: every individual judge verdict in the run.
- Agent snapshots: the frozen agent configurations the run scored against.
- Summary: aggregate means (overall, text, audio), target match counts, and whether the run passed its threshold.
QUEUED means the run is alive but its judge calls are waiting at the provider rate limit. PARTIAL means the run finished with some calls graded and some failed.
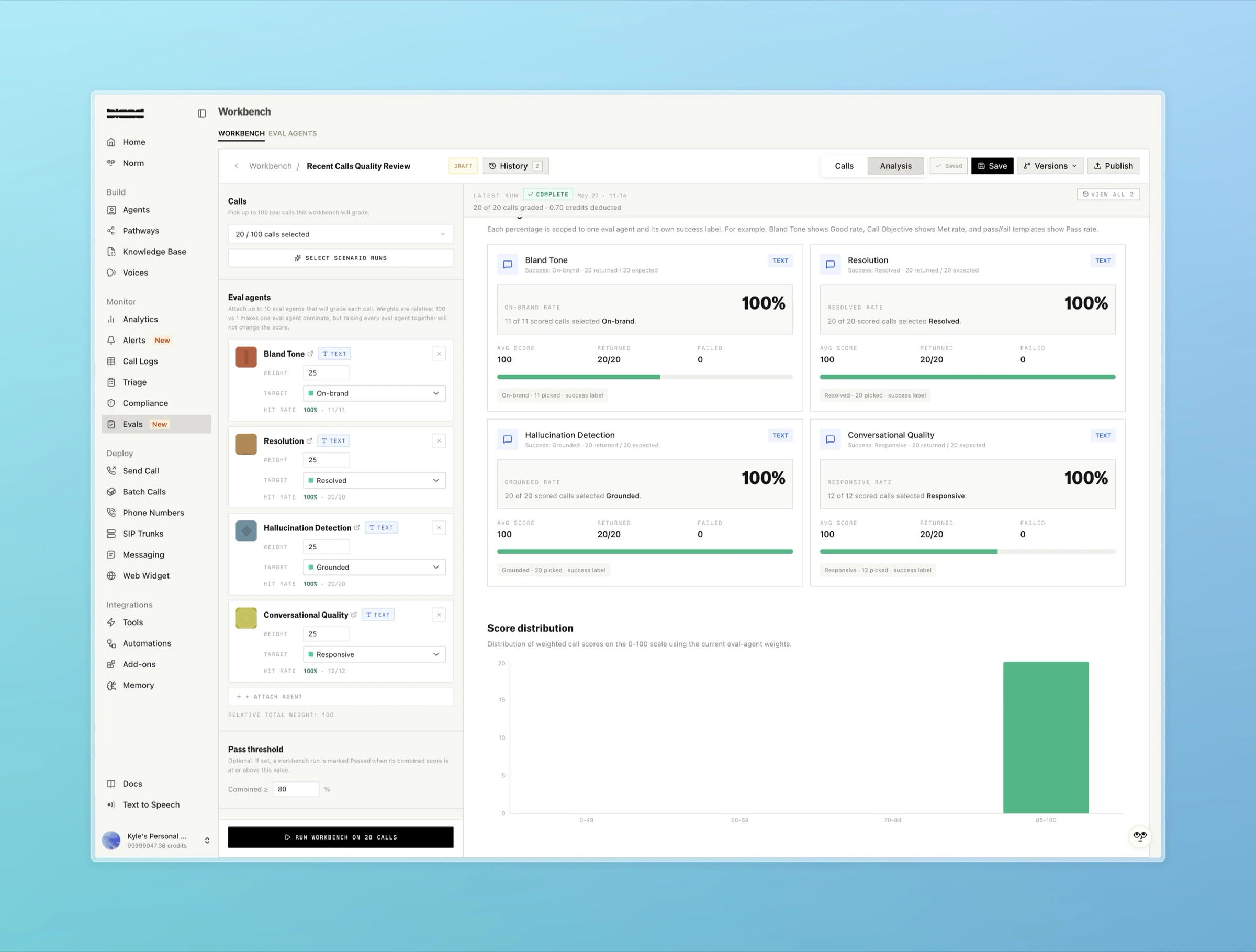
Workbench setups
A workbench setup is a saved, named, versioned bundle of attached agents, their weights and targets, a pass threshold, a run mode, and an optional default call selection. Setups give a recurring evaluation a stable identity, so you can re-run the same composition and compare results over time. Like eval agents, setups are versioned with a draft and a published active version. When you start a run from a setup, the run pins the setup version it used, so editing the setup afterward does not change that run’s results. A published setup can also be attached to a Persona from its Analysis tab to score every call that persona handles automatically once the call ends.Templates
Templates are starting points for new eval agents:- Shipped templates: a read-only library of curated agents covering common qualities: Hallucination Detection, Resolution, Conversational Quality, Bland Tone, Audio Quality, Discovery, Issue Understanding, Objection Handling, Scheduling Clarity, and Appointment Booked.
- User templates: agents your organization saves for reuse. Save an existing agent as a template, then create new agents from it.
How scoring works
For each call in a run, every attached agent of a matching modality produces a verdict. The verdict’sscore_normalized_0_100 is combined across agents using their weights to produce the call’s overall score. The run’s summary averages these across all calls and compares the result against the pass threshold to decide overall_pass.
Verdicts marked is_insufficient_evidence or that failed to grade are excluded from the averages so they do not dilute the score.
Using the API
The Evals API is rooted at/v1/evals. A typical end-to-end flow:
1
Check access
Call
GET /v1/evals/status to confirm Evals is enabled for your organization.2
Create an eval agent
POST /v1/evals/agents, optionally from a template_key. Edit its draft version with PATCH /v1/evals/agents/{id}/versions/{version_id}, then publish with POST /v1/evals/agents/{id}/publications.3
Estimate and run
Preview cost with
POST /v1/evals/runs/estimates, then start the run with POST /v1/evals/runs.4
Read results
Poll
GET /v1/evals/runs/{run_id} for status, then fetch call results and agent results.workbench_setup_id plus workbench_setup_version_id when creating a run.
Auto-running evals after a call
Instead of submitting eval runs manually, you can attach a workbench setup to a call at creation. When the call completes, Bland automatically runs that workbench against the call. Passpost_call_evals on POST /v1/calls with your workbench_setup_id, or pin an exact workbench_setup_version_id:
- Recording is required. Eval judges run against the recording, so calls with
post_call_evalsare recorded automatically. If you explicitly setrecord: false, the request is rejected. - The setup version is pinned at call creation. Editing the workbench mid-call does not change what gets evaluated, mirroring how manual eval runs pin the version at submission.
- The main post-call webhook acknowledges the attachment with
post_call_evals: { workbench_setup_id, workbench_setup_version_id, status: "pending" }. Eval scores arrive later on a separateevalswebhook event when the run finishes. - Auto runs appear alongside manual runs. Filter for them with
triggered_by=autoonGET /v1/evals/runs. - Strip the field from webhooks by adding
post_call_evalsto your organization’swebhook_excluded_fieldspreference.